Recently, I’m trying to explore potential applications of LLMs in SE tasks, such as Automated Program Repair and Static Analysis. And the capabilities of LLMs on these tasks are build on their syntactic understanding of programming languages. What’s more, I’m also insterested in what extent can LLMs be used to understand and programming languages.
So I read this paper, ICSE-NIER’24: Which Syntactic Capabilities Are Statistically Learned by Masked Language Models for Code?.
In this paper the authors find that LLMs under study fail to predict some syntactic capabilities.
Methodology
In this paper, the authors proposed a evaluation method named SyntaxEval.
Its evaluation process mainly consisted of two steps:
-
Evaluating syntactic capabilities:
- It first find one AST node type to be analyzed and then replace all AST node of this type in the AST with label
<mask>. - Employ the tested MLM to infer the masked tokens, and then travel the AST using in-order traversal algorithm.
- Compute 3 similarity metrics (i.e., Jaccard, Levenshtein and Sorensen-Dice) of the list of predicted nodes and the ground truth nodes.
- It first find one AST node type to be analyzed and then replace all AST node of this type in the AST with label
-
Evaluating Causal Interpretabiltiy:
- To analyze the performance of MLMs on the masked source code, SyntaxEval design a treatment T which randomly masked same amount of tokens in the source code.
- It calculate Average Treatment Effect () = E [Y - Y] to see the effect of each treatment.
Results
In their experiment:
-
T (treatment 0): mask source code randomly.
-
T (treatment 1): mask source code by AST node type.
-
Dataset: 50k python snippets from github span from 2022.01.01 to 2022.12.31, and sampled 8k for experiment.
They apply SyntaxEval on two MLMs:
| Id | MLM | Size | Layers | Vocab. |
|---|---|---|---|---|
| M₁ | CodeBERTa-small-v1 | 84M | 6 | 52,000 |
| M₂ | codebert-base-mlm | 125M | 12 | 50,265 |
The results found:
-
The performance of and are similar, no siginificant difference. Even the performance of is lower than , indicating the MLMs can not learn syntactic capabilities.
-
Furthermore, the results in Figure2 also shown that the MLM struggle to predict AST node type
comparison_operatorandstring, etc, only perform better onidentifier.
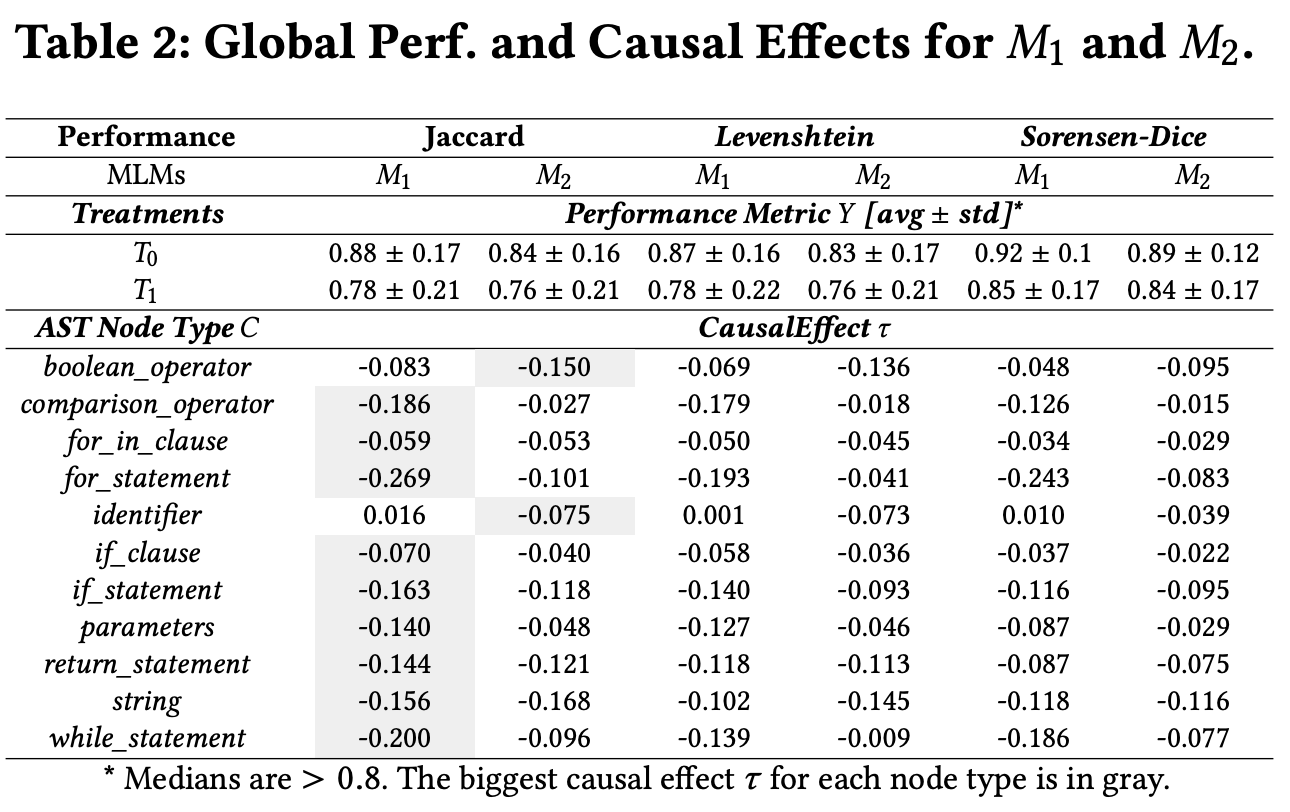

- Considering the Causal Interpretability, the authors found the T have negaitive effect on the performance of MLMs as shown in Table2. This suggests that although transformers are predicting AST node types with confidence (performance in Table2 is relativly high), these syntactic features are not particularly relevant compared to predicting any other set of unstructured tokens in the snippet.
Conclusion
This paper proposed an interesting 2-step evaluation method to evaluate the syntactic capabilities of MLMs. And find the MLMs are not understanding syntax rules of PLs. Recently, there are many SE works apply LLM/MLMs on code generation / program repair / etc tasks, and many of them have shown the limitation of the LLM’s reasoning capabilities. This paper provides a new perspective to understand the syntactic capabilities of LLMs, and it is worth further exploration of how to combine LLM/MLMs with more SE domain knowledge to enhance their capabilities in practice.